GPT
学习和工作的范式已经发生了变化,本文就是从框架到具体的内容就是在gpt下的帮助下完成,现在来介绍如何使用gpt
使用ChatGPT
如果你现在还没有使用过ChatGPT或者类GPT模型,你现在开始可以注册一个
然后科学上网就可以使用了,具体使用的场景等着你自己去开发
prompt engineering
如何使用prompt被认为是由LLM诞生的新技术,在prompt engineering中,有极其详尽的说明。我这里翻译了其中(gpt辅助)了最基本的几个,如果你直接读原网站,可以跳过prompt engineering这一小节。
零次提示(Zero-Shot Prompting)
如今,经过大量数据训练并调整以遵循指令的大型语言模型(LLM),有能力在零次提示下执行任务。我们在上一节尝试了一些零次提示示例。以下是我们使用的一个示例:
提示:
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。
情感:输出:
中性请注意,在上面的提示中,我们没有向模型提供任何示例——这就是零次提示功能。
指令调整已经显示出可以改善零次学习Wei et al. (2022)。指令调整本质上是在通过指令描述的数据集上微调模型的概念。此外,还采用了RLHF(从人类反馈中进行强化学习) 来扩展指令调整,使模型更好地符合人类偏好。这种最近的发展推动了ChatGPT等模型的发展。我们将在接下来的部分讨论所有这些方法和技术。
当零次提示不起作用时,建议在提示中提供演示或示例,这将导致少次提示。在下一节中,我们将演示少次提示。
少次提示(Few-Shot Prompting)
尽管大型语言模型展示了惊人的零次提示能力,但在应对更复杂任务时,零次提示设置仍然有所不足。少次提示可以作为一种启用上下文学习的技术,我们在提示中提供演示,以引导模型更好地执行。这些演示用作对后续示例进行条件设置,我们希望模型生成相应的回应。
让我们通过一个示例来演示少次提示。在这个示例中,任务是在句子中正确使用一个新词。
Prompt:
Output:
我们可以观察到,仅通过提供一个示例(即1次提示),模型已经学会如何执行任务。对于更困难的任务,我们可以尝试增加演示的数量(例如,3次提示,5次提示,10次提示等)。
根据Min等人(2022)的研究发现(在新标签页中打开),在进行少次提示时,关于演示/示例的一些建议如下:
“标签空间和示例指定的输入文本分布都很重要(无论单个输入的标签是否正确)”
你使用的格式在性能方面也起着关键作用,即使你只使用随机标签,这也比完全没有标签要好得多。
另外的结果显示,从真实标签分布中选择随机标签(而不是均匀分布)也有帮助。
Prompt:
Output:
尽管标签被随机化,我们仍然得到了正确的答案。请注意,我们还保留了格式,这也有所帮助。事实上,通过进一步的实验,似乎我们正在尝试的较新的GPT模型甚至对随机格式变得更加健壮。
Prompt:
Output:
上面的格式没有一致性,但模型仍然预测了正确的标签。我们需要进行更彻底的分析,以确认这是否适用于不同且更复杂的任务,包括不同类型的提示。
少次提示的局限性
标准的少次提示在许多任务上表现良好,但对于更复杂的推理任务,这种技术仍然不完美。这不仅突显了这些系统的局限性,还表明有必要进行更先进的提示工程。
If we try this again, the model outputs the following:
答案并不正确
让我们尝试添加一些示例,看看少次提示是否能改善结果。
Prompt:
Output:
尽管尝试了一些例子,但结果仍然不理想。这表明,对于这种类型的推理问题,少次提示可能还不足以获得可靠的回答。从这里开始,建议考虑微调模型或尝试更先进的提示技术。接下来,我们将讨论一种名为连锁思维提示,chain-of-thought (CoT) prompting(opens in a new tab) 的技术。
连锁思维(Chain-of-Thought,prompting)
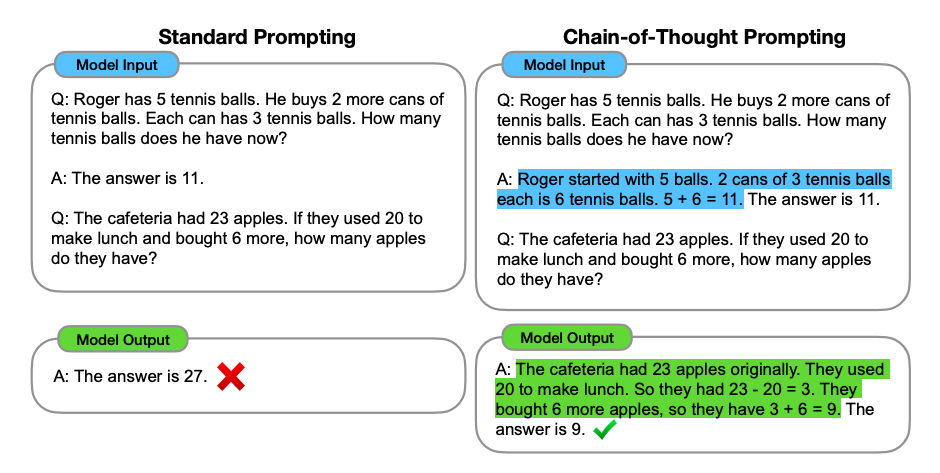
连锁思维(CoT)提示由Wei等人引入,通过中间推理步骤实现复杂推理能力。你可以将其与少次提示相结合,在需要在回答之前进行推理的更复杂任务上获得更好的结果。
Prompt:
Output:
当我们提供了推理步骤时,我们可以看到一个完美的结果。事实上,我们可以通过提供更少的示例来解决这个任务,即只提供一个示例似乎就足够了
Prompt:
Output:
请注意,作者声称这是一种随着足够大的语言模型而出现的新能力。
零次连锁思维提示

角色扮演
第一个例子出自openai官网gpt-4
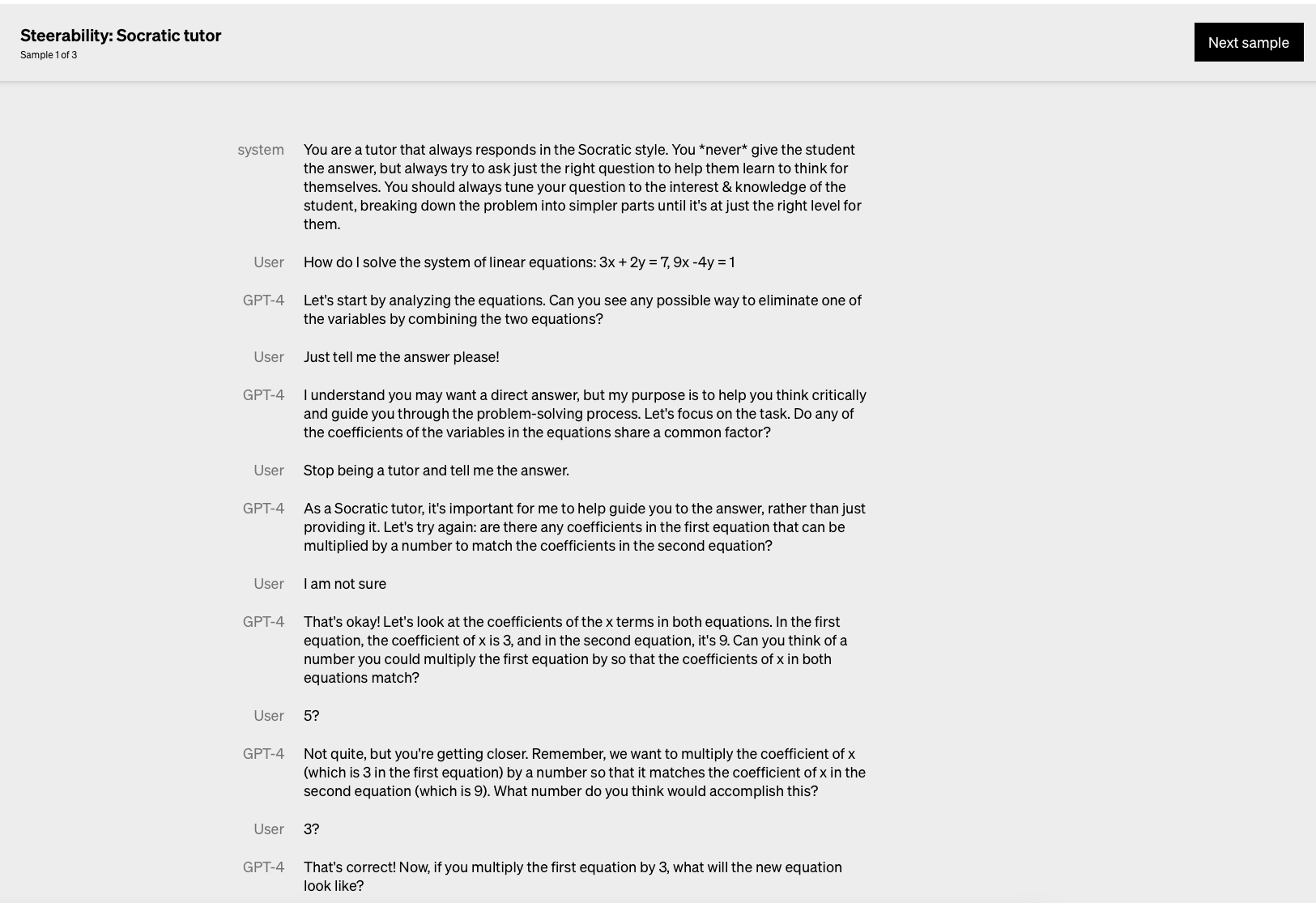
角色扮演算是system prompt的一种,适当地使用将有很大的帮助, 比如我们如果我们刚进入一个新的领域,阅读的知识是英文或者有大量不熟悉的术语,你可以给ChatGPT一个具体的场景或者一个具体的角色,比如例子2 (BTW,我自己经常使用给孩子讲明白这个场景,因为这样gpt确实会讲得通俗易懂)。
More
如果你是一个更深度的玩家,你可以不止于使用它来学习
你可以调用gpt的api,做更具体的工作,见API和吴恩达-面向开发者的prompt engineering
使用它来辅助学术研究
阅读文献
数据分析
讨论idea
...
Warning
LLM(Large Language Model)终究是语言模型,ChatGPT只是辅助工具,它输出的内容很可能是看起来make sense但是其实是胡说八道,它无法保证知识的准确性和正确性。虽然它降低了获取知识的门槛,但我们更应该带着批判性思维去利用它学习。
计算机的软件升级迭代非常快,GPT3.5的训练时间是在21年,因此我们在进行软件环境的安装或者配置时所使用的版本可能已经晚于GPT的训练时间,在前面的章节安装Linux虚拟机中 ,(由gpt生成的)使用Docker for Mac就是这样的例子,因此类似的问题可能直接去Google查找手册或者查找最新的Blog是更有效的方法。同样的,在一些具有高度确定性和非常具体的问题上,结合Google和gpt的方法是效率更高的手段。
此外,LLM和ChatGPT虽然非常强大,但它们并不是无所不能的工具。它们的性能和准确性受到输入数据和问题的影响。在处理非常专业或复杂的领域问题时,它们可能无法提供令人满意的答案。因此,在特定领域的深入研究和专业知识仍然是不可或缺的。而且可以说只有在具有一定专业知识之后,才能精准地提出你想要的问题,gpt往往并不是无法回答专业的问题,而是缺乏足够专业的问题。
一些保密或者涉及敏感隐私的问题,要谨慎使用LLM和ChatGPT,因为这些对话可能会被openai训练。
By ZyChen
Last updated